Cuckoo 2.0.7 流程分析
Cuckoo官方说明中提到:
Cuckoo Sandbox 由处理样本执行和分析的中央管理软件组成。
每个分析都在一个全新的、隔离的虚拟机或物理机中启动。Cuckoo 基础设施的主要组件是一台主机(管理软件)和一些访客机(用于分析的虚拟或物理机)。
Host 运行沙箱的核心组件,管理整个分析过程,而 Guest 是隔离的环境,恶意软件样本在其中真正安全地执行和分析。
下图解释了 Cuckoo 的主要架构:
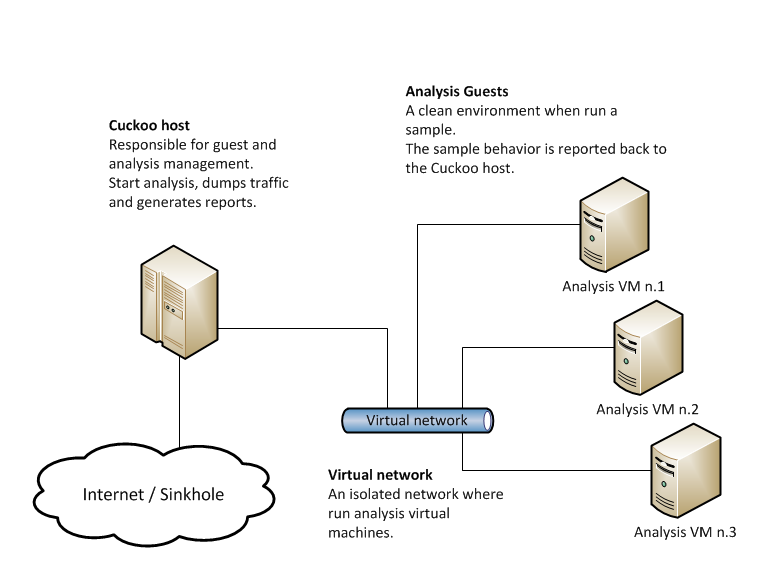
那么我们从操作手册中可以知道,main.py是Cuckoo的服务脚本,agent.py是客户机上运行的脚本,下面就两个脚本进行分别探究。
main.py
通过以下命令可以确定cuckoo的启动脚本位置:
(venv) cuckoo@ubuntu:~$ cat $(which cuckoo)
#!/home/cuckoo/venv/bin/python2
# -*- coding: utf-8 -*-
import re
import sys
from cuckoo.main import main
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0])
sys.exit(main())
也就是Github仓库中的main.py
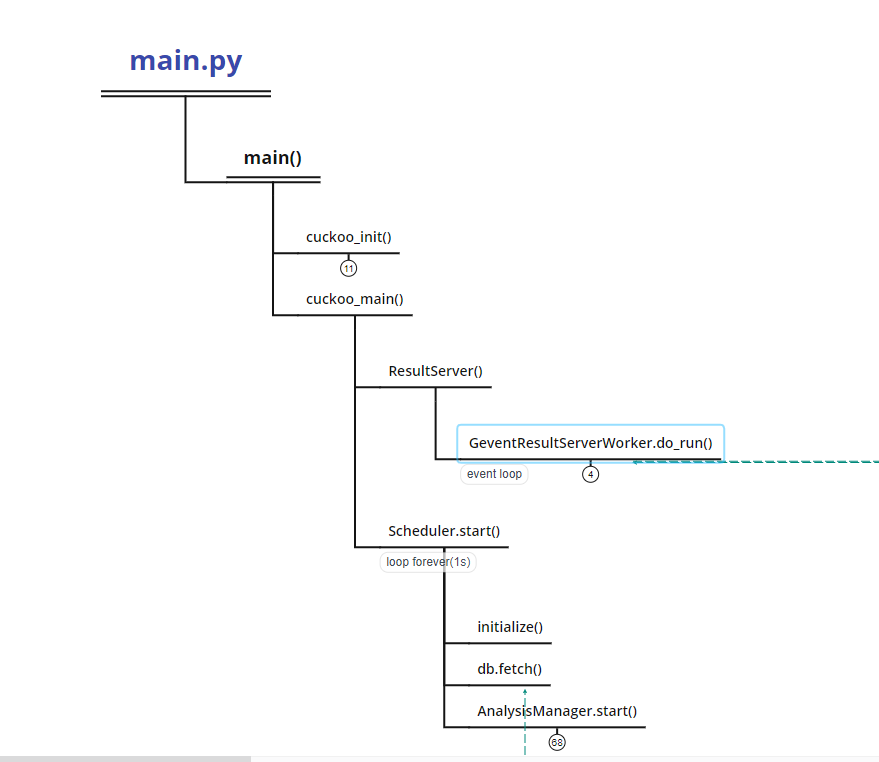
运行main(),首先是cuckoo_init()初始化,初始化内容如下:
cuckoo_resources()
check_configs()
check_version()
Database().connect()
load_signatures()
init_modules()
init_tasks()
init_yara()
init_binaries()
init_rooter()
init_routing()
然后进入cuckoo_main(),主要启动两个服务。
- 启动
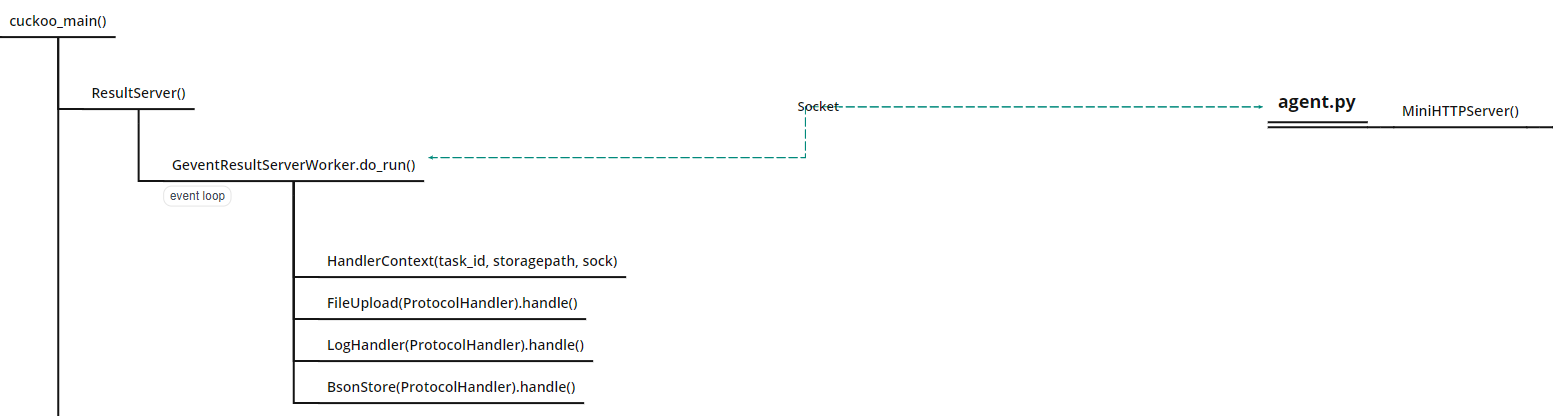
ResultServer(),使用gevent.server与agent构建通信;
- 开启
Scheduler.start(),用于执行数据库中的待分析任务,最直接的方式是通过submit参数提交,当然还有rest api和web上传,不过最终都是将任务添加到数据库中,由Scheduler循环检测数据库,执行相关分析任务。
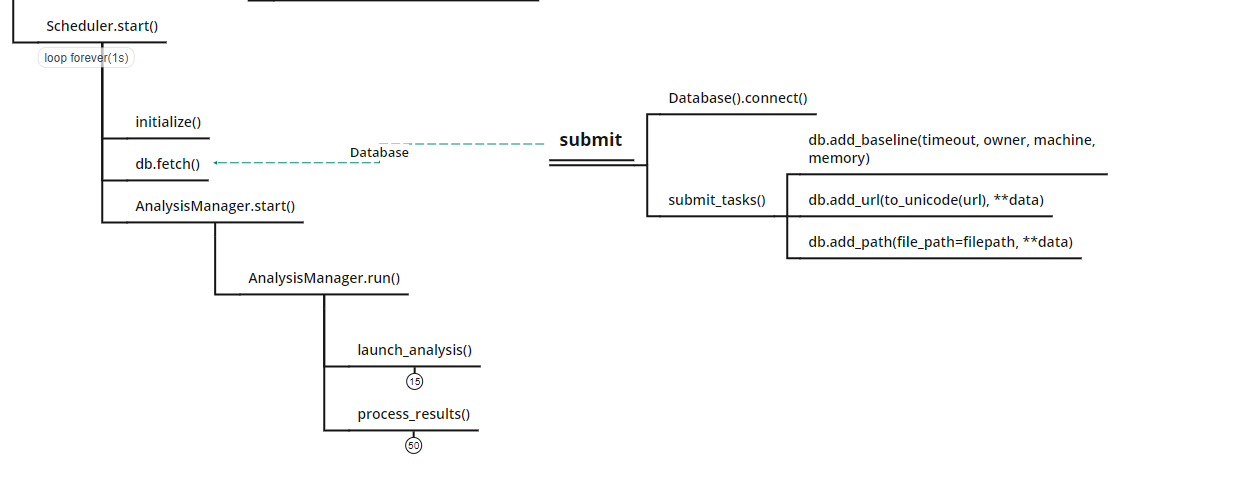
然后新建一个线程执行AnalysisManager.run(),这是分析类的汇总,包含了开始分析(launch_analysis())以及产出报告(process_results())。
launch_analysis()
包括了初始化分析函数、获取分析客户机、告知ResultServer服务分析机器标识、初始化分析机器、调用辅助模块、生成配置文件、启动分析虚拟机、启用网络路由、开始分析。
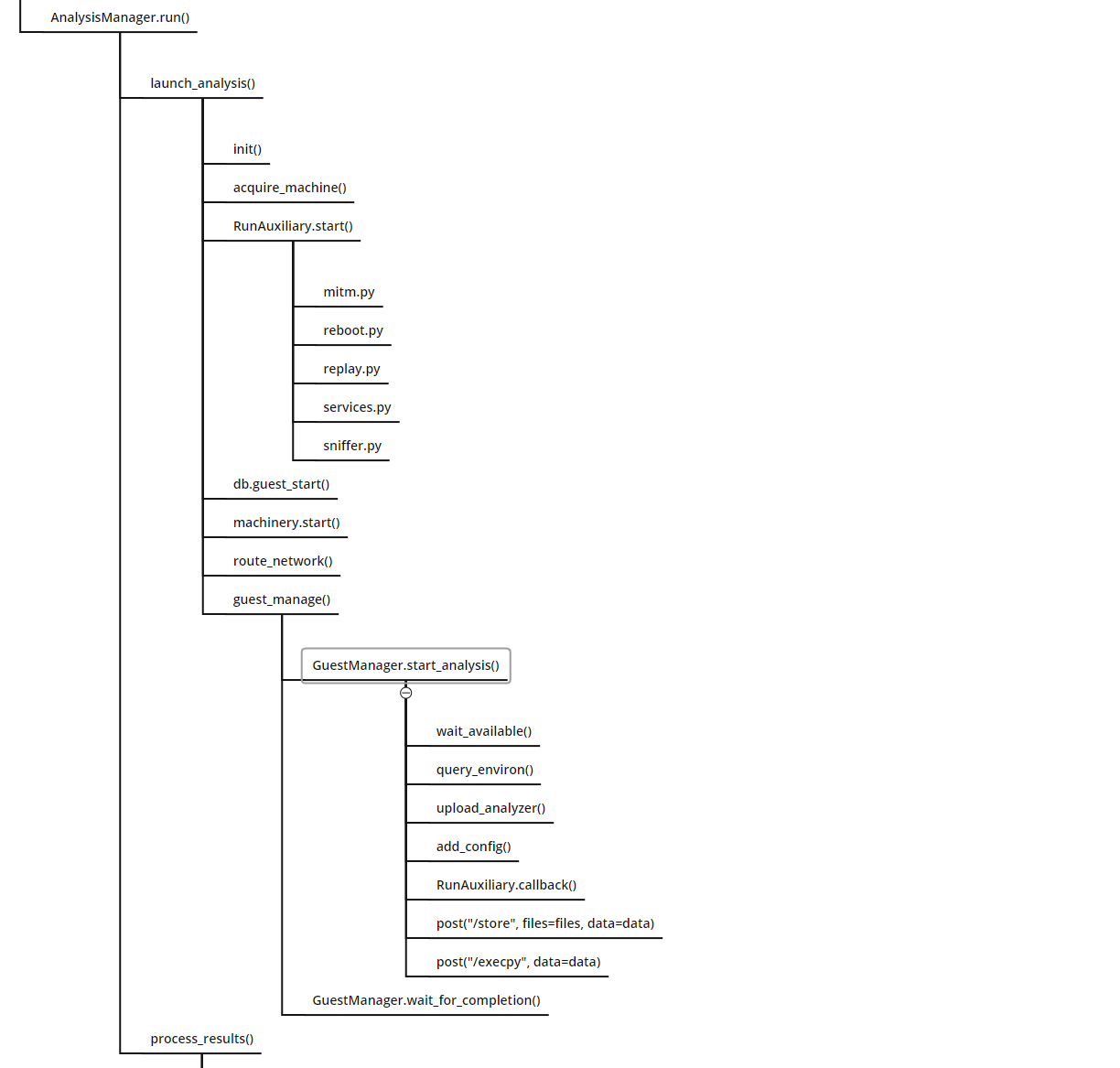
当然最主要的是guest_manage()函数,它直接调用了GuestManager.start_analysis()开始分析,该分析函数的主要逻辑如下:
- 等待虚拟机可用
- 检查客户机状态是否为开启
- 新旧代理检查
- 设置静态ip
- 获取虚拟机中agent的环境变量
- 上传分析文件
- 上传配置文件
- 允许辅助模块接入客户机
- 转储样本文件
- 执行
analyzer.py
至此,分析的流程转交给了在客户机执行的analyzer.py,服务只需要等着返回结果生成报告即可。
process_results()
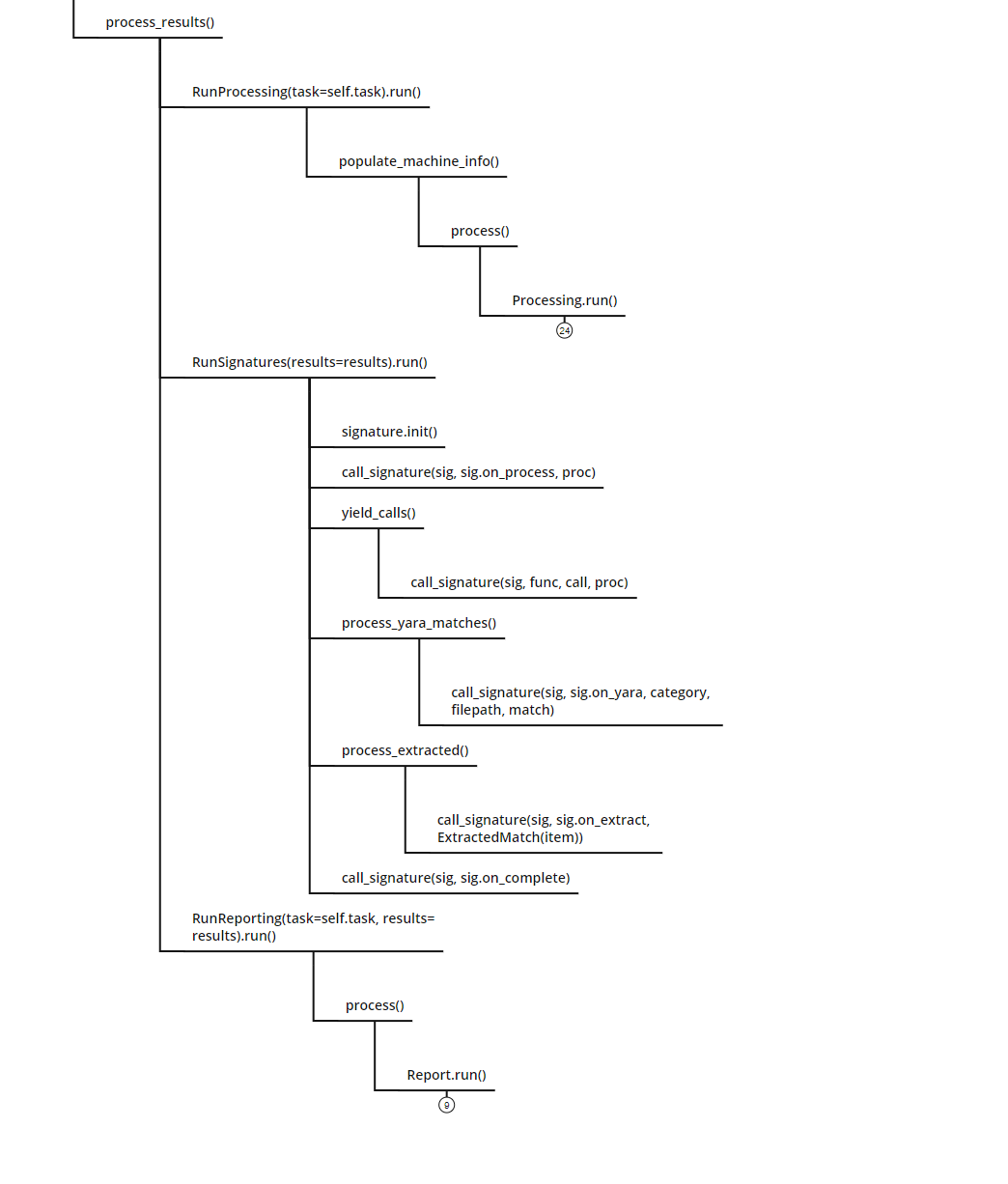
该结果分析是由三个大类依次处理的:
- RunProcessing():对分析结果进行处理。在Cuckoo的源码目录中提供了
processing文件夹,其中包含了许多的处理模块,在Cuckoo的说明手册中指出,我们可以根据框架模块自定义分析功能。 - RunSignatures():对签名特征进行匹配。Cuckoo提供一个社区版的signature库,里面包含了官方和其他用户创建好的可用签名,当然,这个部分也是可以自定义的
- RunReporting():对处理结果进行上报。在Cuckoo的源码目录中提供了
reporting文件夹,其中包含了许多报告模板,我们可根据语法,自定义报告模板内容。
agent.py
这个部分是采用了SimpleHTTPServer开启了一个web服务与ResultServer()产生交互,当Cuckoo server端访问客户机/execpy路径时,将触发do_execpy()函数执行上传的analyzer.py,开始进行分析任务。

analyzer.py
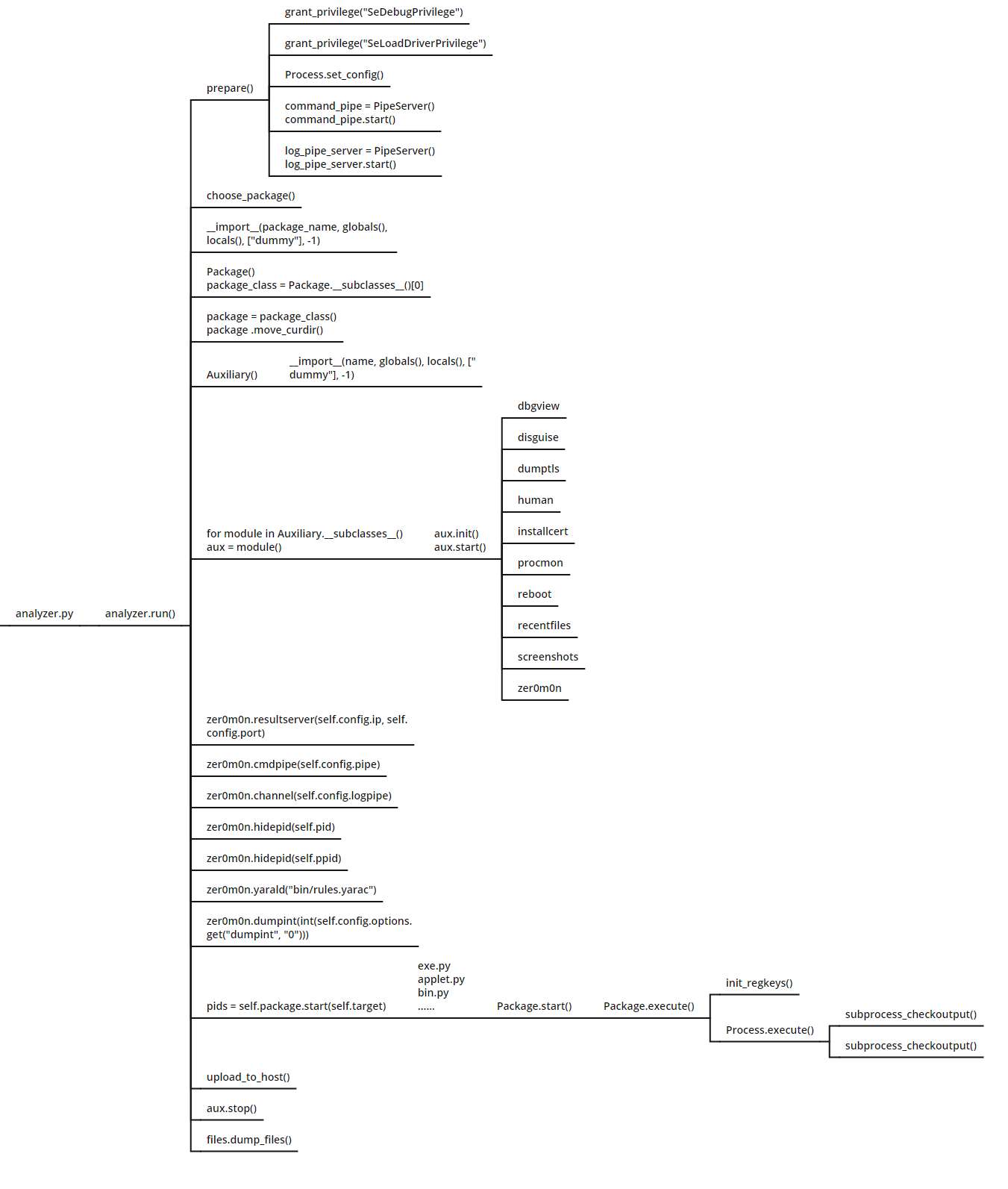
关键的分析流程来了:
- 首先是运行
prepare()执行一些准备工作:提升权限、解析analysis.conf、传递配置给进程、设置虚拟机事件、创建监视管道和日志管道、获取样本路径; - 根据样本后缀名,获取样本的文件类型,移动样本到指定的缓存路径;
- 导入辅助模块并执行;
- 向内核驱动模块传入必要参数;
- 根据样本类型,执行相应的样本分析脚本;
- 分析结束后上传结果;
- 终止辅助模块;
- 转储所有挂载文件;
其中需要重点关注的就是执行相应的样本分析脚本,这里以exe.py为例:
- 脚本启动后将调用
Package.execute()。其中包含了初始化注册表和调用Process.execute() Process.execute()的功能是执行样本和实现注入
至此流程分析结束。
总结
完整图例如下:
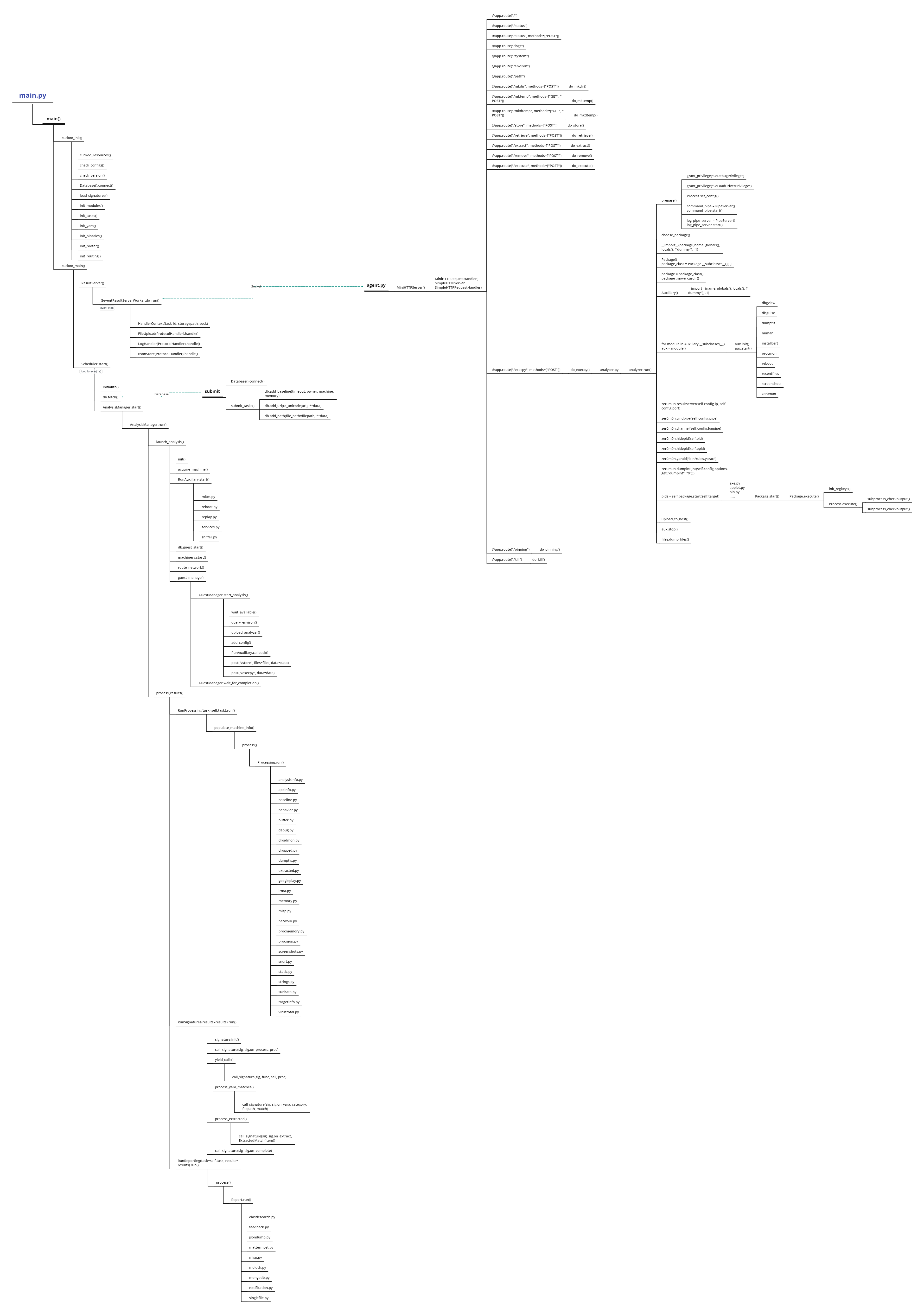
至于Cuckoo的执行流程,可以这样简述:
- server端启动Cuckoo服务;
- 构建与client的socket通信;
- 连接本地数据库,读取等待执行的任务;
- 获取任务,提交给client等待处理;
- client接收任务,创建本地缓存并执行分析脚本;
- 分析脚本执行注入程序,启动样本并进行注入;
- 等待分析结束,上传结果至server端;
- 处理client端上传的结果,形成报告;